BBS seminar 1st November 2019: Predictive modelling, machine learning, and causality
1 Introduction
On 1st November 2019, the BBS organized a seminar on Predictive modelling, machine learning, and causality with several eminent speakers. The full program including abstracts of all talks is available here.
2 Summary
In total, 256 people registered for the event and both pharma and academia were well represented amongst speakers and participants.
The introductory talk was by Ewout Steyerberg on “Clinical prediction models in the age of artificial intelligence and big data”. Ewout set the scene by dispelling five myths around big data and ML/AI:
- Big Data will resolve the problems of small data \(\Rightarrow\) NO: Big Data, Big Errors
- ML/AI is very different from classical modeling \(\Rightarrow\) NO: a continuum, cultural differences
- Deep learning is relevant for all medical prediction \(\Rightarrow\) NO:Deep learning excels in visual tasks
- ML/AI is better than classical modeling for prediction \(\Rightarrow\) NO: some methods do harm (e.g. tree modeling)
- ML/AI leads to better generalizability \(\Rightarrow\) NO: any prediction model may suffer from poor generalizability
Willi Sauerbrei gave a thorough talk on guidelines. He highlighted the importance of the reporting guidelines from the Equator network for all types of studies including RCTs (CONSORT and extensions) or diagnostic/prognostic studies (STARD and TRIPOD). Willi also mentioned many other important initiatives including the STRATOS initiative which aims to o provide accessible and accurate guidance in the design and analysis of observational studies.
Torsten Hothorn gave a presentation on “Score-based Transformation Learning”. He showed that boosting, trees, and forests can be understood as algorithms leveraging the information contained in residuals or scores for increasing model complexity. The starting point is any appropriate model (and corresponding log-likelihoods and scores) featuring interpretable parameters. In particular, transformation models (which include most conventional regression models including Cox regression) are a convenient starting point. Torsten also provided references to his R packages to implement these methods and demonstrated boosting with nice web-apps (click on the models on Slide 35 of his presentation to see them).
Peter Bühlmann presented on “Causal Regularization for Distributional Robustness and Replicability”. He discussed the problem of using data from several heterogeneous populations to make predictions for a new population with a different data-generating mechanism. The proposed approach to achieve replicability in such settings builds on distributional robustness and borrows ideas from causality. On the spectrum from marginal correlation - regression - invariance - causality, the proposed method of anchor regression is “one step closer” to true causality than conventional regression.
Several case studies were presented: Giusi Moffa gave an introduction to directed acyclic graphs (DAGs) with an application in psychiatry. Andrew Shattock showed how mathematical models can be used to assess the potential impact of interventions to achieve health goals in malaria and used a Gaussian process emulator with adaptive sampling to explore the large paramater space (his slides cannot be shared publicly). Federico Mattiello presented on prognostic models which aim to identify high-risk patients in follicular lymphoma.
The two last talks provided longer case studies from Pharma. Mark Baillie gave a talk on the Novartis benchmarking initiative to systematically evaluate vendors of AI/ML solutions. Interestingly, Mark proposed to assess the quality of reporting by the vendors’ adherence to reporting guidelines such as TRIPOD which nicely aligned with the earlier talk by Willi Sauerbrei. Chris Harbron gave the final talk on experiences from running internal prediction challenges within a pharmaceutical company (Roche). He highlighted the many benefits that such initiatives have including promoting advanced analytics across the company and promoting cross disciplinary and cross organisation interactions (a recent challenge had 517 participants which formed 141 teams across 38 Roche sites). He also explored the role of consensus scoring to improve individual predictions models.
The succesful event ended with a panel discussion and the annual general assembly of the BBS.
3 Slide decks for download
Moffa pdf slides / github slides
Shattock (slides cannot be shared publicly)
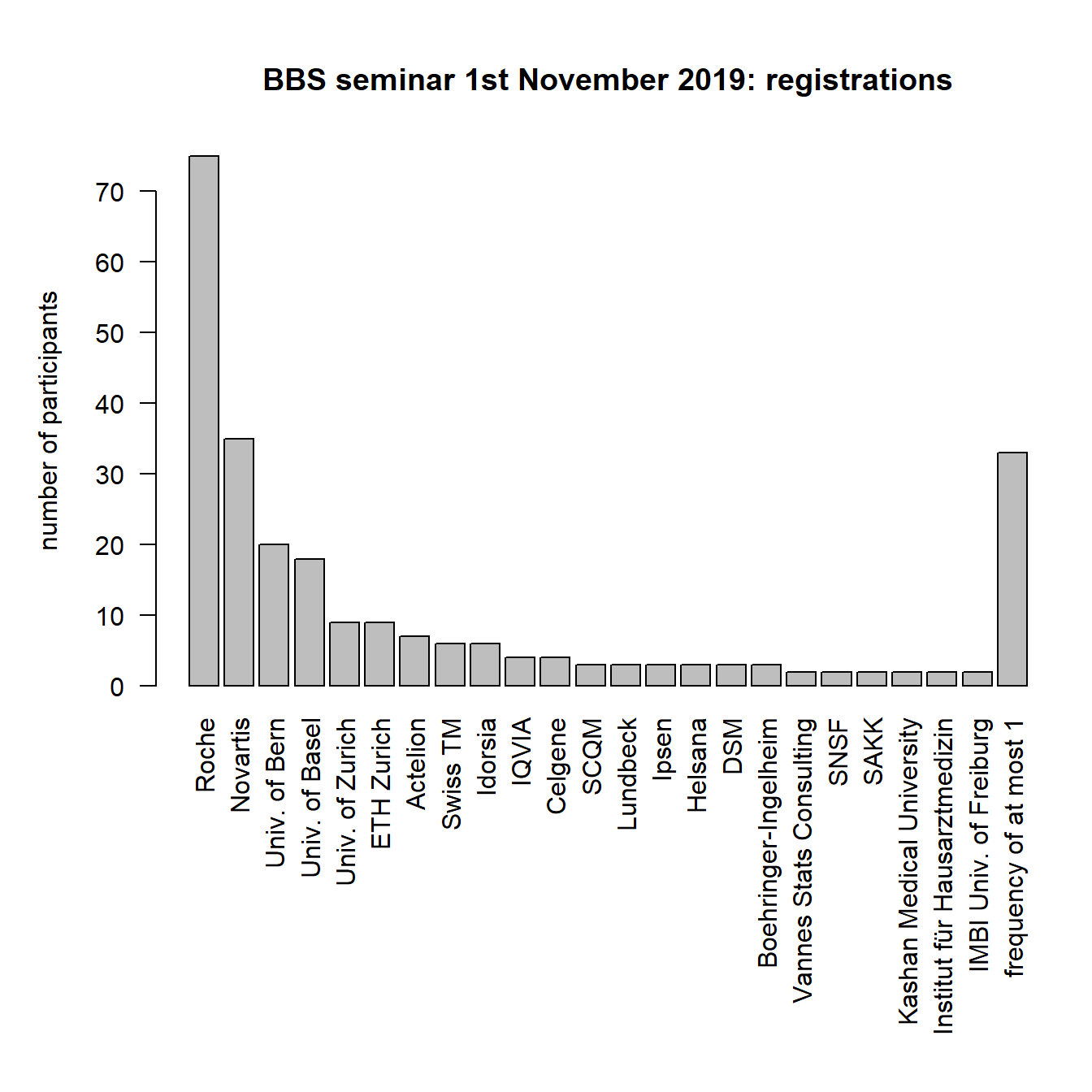
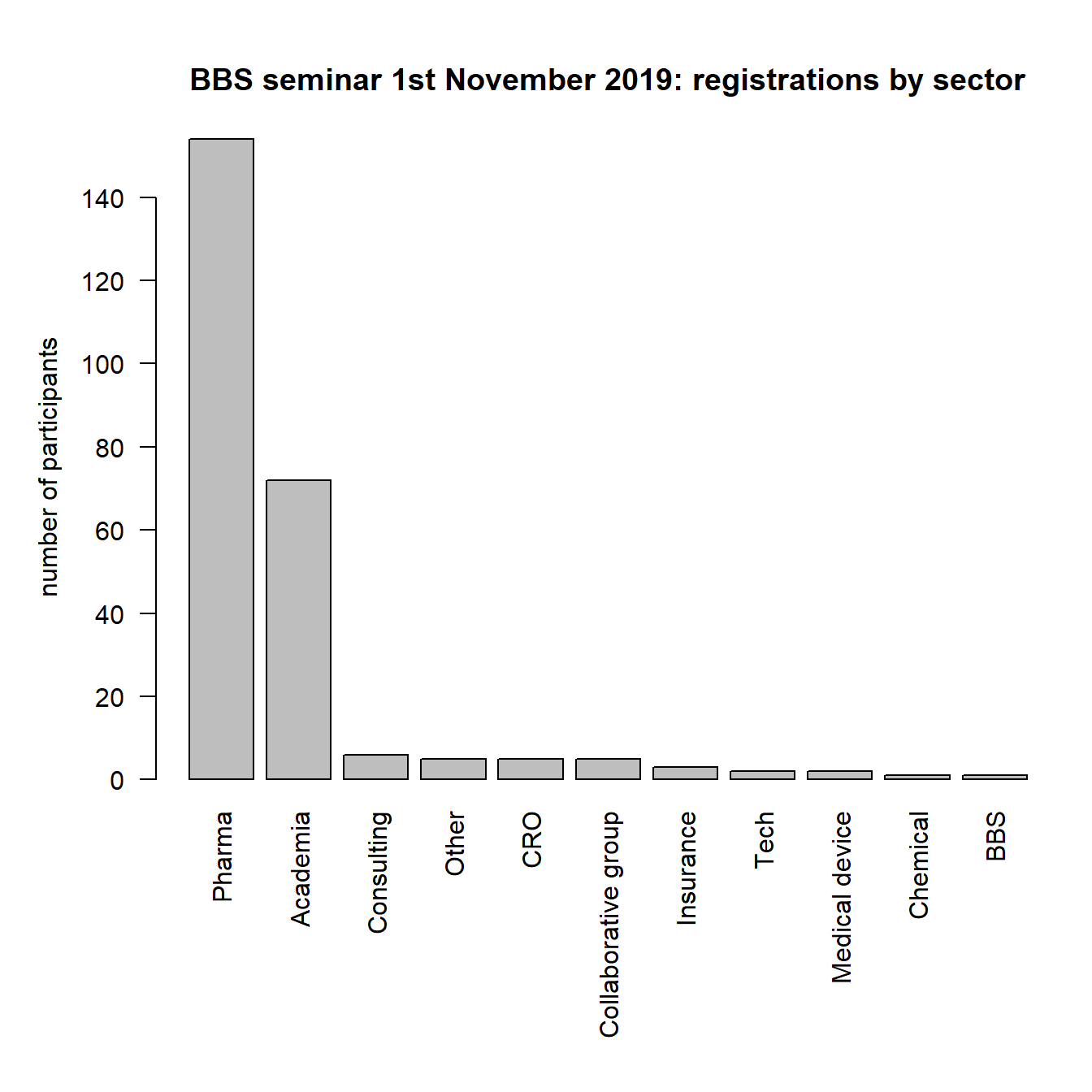
4 Registrations
In total, 256 people registered for the event. The distribution on institution and sectors is available below.
4.1 By institution
Institutions with a frequency of at most 1: Xcenda / Univ. of Neuchatel / Univ. of Lausanne / Univ. of Heidelberg / Univ. of Freiburg / Univ. de Cote d’Azur / Univ, of Lucerne / PWC / Merck Group / Medtronic / Livanova / Janssen / ISPM / Imito / HTWG Konstanz / Genentech / FHNW / Feinstein Institute / Erasmus Univ. / EAWEG / DFFZ Heidelberg / Corteva / Constat / ClinStat / Certara / CEB / Biogen / Bern Hochschule / BBS / AZ / Ava / Arete / AbbVie
4.2 By sector (manually categorized)
5 Pictures










6 Feedback and contact
We are more than happy to receive your feedback! Please feel free to reach out to any or all of the organizers by sending an email to firstname.lastname@roche.com.